While some people feel that GiveWell puts too much emphasis on the measurable and quantifiable, there are others who go further than we do in quantification, and justify their giving (or other) decisions based on fully explicit expected-value formulas. The latter group tends to critique us – or at least disagree with us – based on our preference for strong evidence over high apparent “expected value,” and based on the heavy role of non-formalized intuition in our decisionmaking. This post is directed at the latter group.
We believe that people in this group are often making a fundamental mistake, one that we have long had intuitive objections to but have recently developed a more formal (though still fairly rough) critique of. The mistake (we believe) is estimating the “expected value” of a donation (or other action) based solely on a fully explicit, quantified formula, many of whose inputs are guesses or very rough estimates. We believe that any estimate along these lines needs to be adjusted using a “Bayesian prior”; that this adjustment can rarely be made (reasonably) using an explicit, formal calculation; and that most attempts to do the latter, even when they seem to be making very conservative downward adjustments to the expected value of an opportunity, are not making nearly large enough downward adjustments to be consistent with the proper Bayesian approach.
This view of ours illustrates why – while we seek to ground our recommendations in relevant facts, calculations and quantifications to the extent possible – every recommendation we make incorporates many different forms of evidence and involves a strong dose of intuition. And we generally prefer to give where we have strong evidence that donations can do a lot of good rather than where we have weak evidence that donations can do far more good – a preference that I believe is inconsistent with the approach of giving based on explicit expected-value formulas (at least those that (a) have significant room for error (b) do not incorporate Bayesian adjustments, which are very rare in these analyses and very difficult to do both formally and reasonably).
The rest of this post will:
- Lay out the “explicit expected value formula” approach to giving, which we oppose, and give examples.
- Give the intuitive objections we’ve long had to this approach, i.e., ways in which it seems intuitively problematic.
- Give a clean example of how a Bayesian adjustment can be done, and can be an improvement on the “explicit expected value formula” approach.
- Present a versatile formula for making and illustrating Bayesian adjustments that can be applied to charity cost-effectiveness estimates.
- Show how a Bayesian adjustment avoids the Pascal’s Mugging problem that those who rely on explicit expected value calculations seem prone to.
- Discuss how one can properly apply Bayesian adjustments in other cases, where less information is available.
- Conclude with the following takeaways:
- Any approach to decision-making that relies only on rough estimates of expected value – and does not incorporate preferences for better-grounded estimates over shakier estimates – is flawed.
- When aiming to maximize expected positive impact, it is not advisable to make giving decisions based fully on explicit formulas. Proper Bayesian adjustments are important and are usually overly difficult to formalize.
- The above point is a general defense of resisting arguments that both (a) seem intuitively problematic (b) have thin evidential support and/or room for significant error.
- I estimate that each dollar spent on Program P has a value of V [in terms of lives saved, disability-adjusted life-years, social return on investment, or some other metric]. Granted, my estimate is extremely rough and unreliable, and involves geometrically combining multiple unreliable figures – but it’s unbiased, i.e., it seems as likely to be too pessimistic as it is to be too optimistic. Therefore, my estimate V represents the per-dollar expected value of Program P.
- I don’t know how good Charity C is at implementing Program P, but even if it wastes 75% of its money or has a 75% chance of failure, its per-dollar expected value is still 25%*V, which is still excellent.
Examples of the EEV approach to decisionmaking:
- In a 2010 exchange, Will Crouch of Giving What We Can argued:
DtW [Deworm the World] spends about 74% on technical assistance and scaling up deworming programs within Kenya and India … Let’s assume (very implausibly) that all other money (spent on advocacy etc) is wasted, and assess the charity solely on that 74%. It still would do very well (taking DCP2: $3.4/DALY * (1/0.74) = $4.6/DALY – slightly better than their most optimistic estimate for DOTS (for TB), and far better than their estimates for insecticide treated nets, condom distribution, etc). So, though finding out more about their advocacy work is obviously a great thing to do, the advocacy questions don’t need to be answered in order to make a recommendation: it seems that DtW [is] worth recommending on the basis of their control programs alone.
- The Back of the Envelope Guide to Philanthropy lists rough calculations for the value of different charitable interventions. These calculations imply (among other things) that donating for political advocacy for higher foreign aid is between 8x and 22x as good an investment as donating to VillageReach, and the presentation and implication are that this calculation ought to be considered decisive.
- We’ve encountered numerous people who argue that charities working on reducing the risk of sudden human extinction must be the best ones to support, since the value of saving the human race is so high that “any imaginable probability of success” would lead to a higher expected value for these charities than for others.
- “Pascal’s Mugging” is often seen as the reductio ad absurdum of this sort of reasoning. The idea is that if a person demands $10 in exchange for refraining from an extremely harmful action (one that negatively affects N people for some huge N), then expected-value calculations demand that one give in to the person’s demands: no matter how unlikely the claim, there is some N big enough that the “expected value” of refusing to give the $10 is hugely negative.The crucial characteristic of the EEV approach is that it does not incorporate a systematic preference for better-grounded estimates over rougher estimates. It ranks charities/actions based simply on their estimated value, ignoring differences in the reliability and robustness of the estimates.
Informal objections to EEV decisionmaking There are many ways in which the sort of reasoning laid out above seems (to us) to fail a common sense test.- There seems to be nothing in EEV that penalizes relative ignorance or relatively poorly grounded estimates, or rewards investigation and the forming of particularly well grounded estimates. If I can literally save a child I see drowning by ruining a $1000 suit, but in the same moment I make a wild guess that this $1000 could save 2 lives if put toward medical research, EEV seems to indicate that I should opt for the latter.
- Because of this, a world in which people acted based on EEV would seem to be problematic in various ways.
- In such a world, it seems that nearly all altruists would put nearly all of their resources toward helping people they knew little about, rather than helping themselves, their families and their communities. I believe that the world would be worse off if people behaved in this way, or at least if they took it to an extreme. (There are always more people you know little about than people you know well, and EEV estimates of how much good you can do for people you don’t know seem likely to have higher variance than EEV estimates of how much good you can do for people you do know. Therefore, it seems likely that the highest-EEV action directed at people you don’t know will have higher EEV than the highest-EEV action directed at people you do know.)
- In such a world, when people decided that a particular endeavor/action had outstandingly high EEV, there would (too often) be no justification for costly skeptical inquiry of this endeavor/action. For example, say that people were trying to manipulate the weather; that someone hypothesized that they had no power for such manipulation; and that the EEV of trying to manipulate the weather was much higher than the EEV of other things that could be done with the same resources. It would be difficult to justify a costly investigation of the “trying to manipulate the weather is a waste of time” hypothesis in this framework. Yet it seems that when people are valuing one action far above others, based on thin information, this is the time when skeptical inquiry is needed most. And more generally, it seems that challenging and investigating our most firmly held, “high-estimated-probability” beliefs – even when doing so has been costly – has been quite beneficial to society.
- Related: giving based on EEV seems to create bad incentives. EEV doesn’t seem to allow rewarding charities for transparency or penalizing them for opacity: it simply recommends giving to the charity with the highest estimated expected value, regardless of how well-grounded the estimate is. Therefore, in a world in which most donors used EEV to give, charities would have every incentive to announce that they were focusing on the highest expected-value programs, without disclosing any details of their operations that might show they were achieving less value than theoretical estimates said they ought to be.
- If you are basing your actions on EEV analysis, it seems that you’re very open to being exploited by Pascal’s Mugging: a tiny probability of a huge-value expected outcome can come to dominate your decisionmaking in ways that seem to violate common sense. (We discuss this further below.)
- If I’m deciding between eating at a new restaurant with 3 Yelp reviews averaging 5 stars and eating at an older restaurant with 200 Yelp reviews averaging 4.75 stars, EEV seems to imply (using Yelp rating as a stand-in for “expected value of the experience”) that I should opt for the former. As discussed in the next section, I think this is the purest demonstration of the problem with EEV and the need for Bayesian adjustments.
In the remainder of this post, I present what I believe is the right formal framework for my objections to EEV. However, I have more confidence in my intuitions – which are related to the above observations – than in the framework itself. I believe I have formalized my thoughts correctly, but if the remainder of this post turned out to be flawed, I would likely remain in objection to EEV until and unless one could address my less formal misgivings.
Simple example of a Bayesian approach vs. an EEV approach It seems fairly clear that a restaurant with 200 Yelp reviews, averaging 4.75 stars, ought to outrank a restaurant with 3 Yelp reviews, averaging 5 stars. Yet this ranking can’t be justified in an EEV-style framework, in which options are ranked by their estimated average/expected value. How, in fact, does Yelp handle this situation?
Unfortunately, the answer appears to be undisclosed in Yelp’s case, but we can get a hint from a similar site: BeerAdvocate, a site that ranks beers using submitted reviews. It states:Lists are generated using a Bayesian estimate that pulls data from millions of user reviews (not hand-picked) and normalizes scores based on the number of reviews for each beer. The general statistical formula is:
weighted rank (WR) = (v ÷ (v+m)) × R + (m ÷ (v+m)) × C
where:
R = review average for the beer
v = number of reviews for the beer
m = minimum reviews required to be considered (currently 10)
C = the mean across the list (currently 3.66)In other words, BeerAdvocate does the equivalent of giving each beer a set number (currently 10) of “average” reviews (i.e., reviews with a score of 3.66, which is the average for all beers on the site). Thus, a beer with zero reviews is assumed to be exactly as good as the average beer on the site; a beer with one review will still be assumed to be close to average, no matter what rating the one review gives; as the number of reviews grows, the beer’s rating is able to deviate more from the average.
To illustrate this, the following chart shows how BeerAdvocate’s formula would rate a beer that has 0-100 five-star reviews. As the number of five-star reviews grows, the formula’s “confidence” in the five-star rating grows, and the beer’s overall rating gets further from “average” and closer to (though never fully reaching) 5 stars.
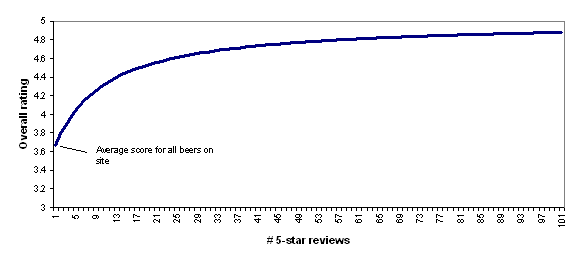
However, there are a couple of complications that make it difficult to apply this approach broadly.
- BeerAdvocate is making a substantial judgment call regarding what “prior” to use, i.e., how strongly to assume each beer is average until proven otherwise. It currently sets the m in its formula equal to 10, which is like giving each beer a starting point of ten average-level reviews; it gives no formal justification for why it has set m to 10 instead of 1 or 100. It is unclear what such a justification would look like.In fact, I believe that BeerAdvocate used to use a stronger “prior” (i.e., it used to set m to a higher value), which meant that beers needed larger numbers of reviews to make the top-rated list. When BeerAdvocate changed its prior, its rankings changed dramatically, as lesser-known, higher-rated beers overtook the mainstream beers that had previously dominated the list.
- In BeerAdvocate’s case, the basic approach to setting a Bayesian prior seems pretty straightforward: the “prior” rating for a given beer is equal to the average rating for all beers on the site, which is known. By contrast, if we’re looking at the estimate of how much good a charity does, it isn’t clear what “average” one can use for a prior; it isn’t even clear what the appropriate reference class is. Should our prior value for the good-accomplished-per-dollar of a deworming charity be equal to the good-accomplished-per-dollar of the average deworming charity, or of the average health charity, or the average charity, or the average altruistic expenditure, or some weighted average of these? Of course, we don’t actually have any of these figures.For this reason, it’s hard to formally justify one’s prior, and differences in priors can cause major disagreements and confusions when they aren’t recognized for what they are. But this doesn’t mean the choice of prior should be ignored or that one should leave the prior out of expected-value calculations (as we believe EEV advocates do).
Applying Bayesian adjustments to cost-effectiveness estimates for donations, actions, etc. As discussed above, we believe that both Giving What We Can and Back of the Envelope Guide to Philanthropy use forms of EEV analysis in arguing for their charity recommendations. However, when it comes to analyzing the cost-effectiveness estimates they invoke, the BeerAdvocate formula doesn’t seem applicable: there is no “number of reviews” figure that can be used to determine the relative weights of the prior and the estimate.Instead, we propose a model in which there is a normally (or log-normally) distributed “estimate error” around the cost-effectiveness estimate (with a mean of “no error,” i.e., 0 for normally distributed error and 1 for lognormally distributed error), and in which the prior distribution for cost-effectiveness is normally (or log-normally) distributed as well. (I won’t discuss log-normal distributions in this post, but the analysis I give can be extended by applying it to the log of the variables in question.) The more one feels confident in one’s pre-existing view of how cost-effective an donation or action should be, the smaller the variance of the “prior”; the more one feels confident in the cost-effectiveness estimate itself, the smaller the variance of the “estimate error.”
Following up on our 2010 exchange with Giving What We Can, we asked Dario Amodei to write up the implications of the above model and the form of the proper Bayesian adjustment. You can see his analysis here. The bottom line is that when one applies Bayes’s rule to obtain a distribution for cost-effectiveness based on (a) a normally distributed prior distribution (b) a normally distributed “estimate error,” one obtains a distribution with
- Mean equal to the average of the two means weighted by their inverse variances
- Variance equal to the harmonic sum of the two variances
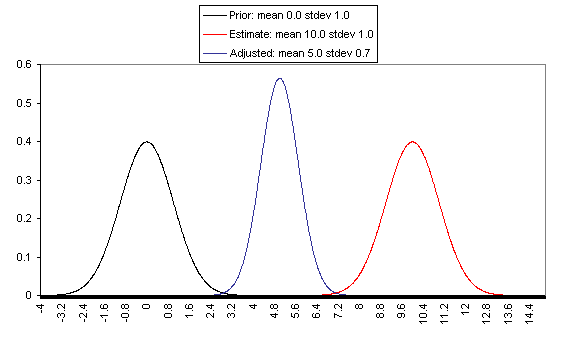
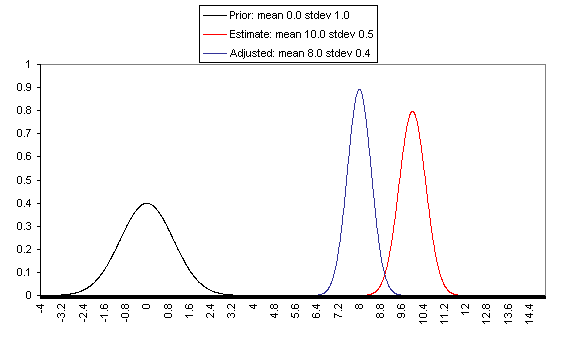
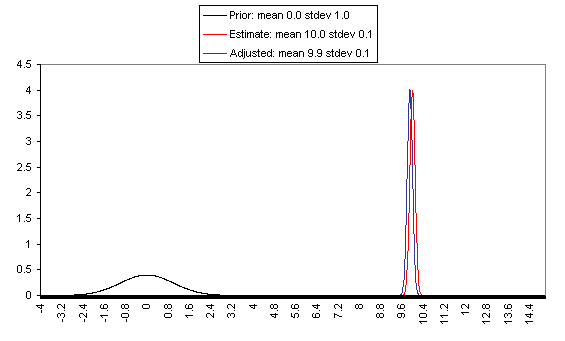
The following charts show what this formula implies in a variety of different simple hypotheticals. In all of these, the prior distribution has mean = 0 and standard deviation = 1, and the estimate has mean = 10, but the “estimate error” varies, with important effects: an estimate with little enough estimate error can almost be taken literally, while an estimate with large enough estimate error ends ought to be almost ignored.
In each of these charts, the black line represents a probability density function for one’s “prior,” the red line for an estimate (with the variance coming from “estimate error”), and the blue line for the final probability distribution, taking both the prior and the estimate into account. Taller, narrower distributions represent cases where probability is concentrated around the midpoint; shorter, wider distributions represent cases where the possibilities/probabilities are more spread out among many values. First, the case where the cost-effectiveness estimate has the same confidence interval around it as the prior:
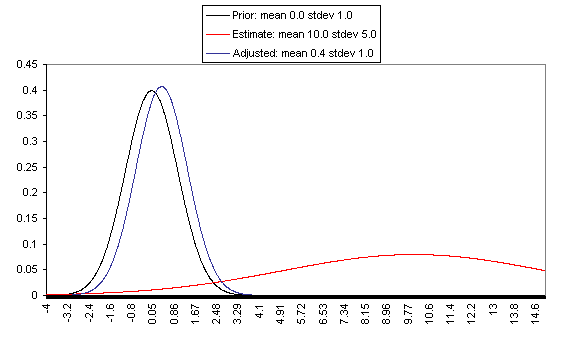
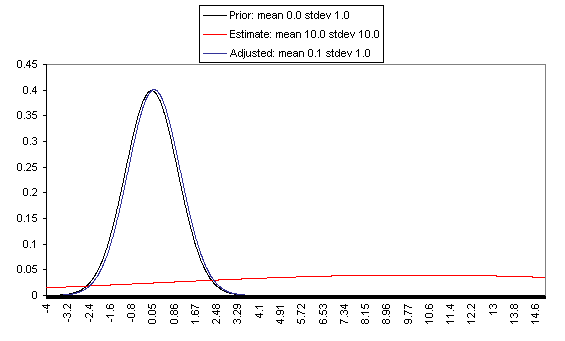
Pascal’s Mugging Pascal’s Mugging refers to a case where a claim of extravagant impact is made for a particular action, with little to no evidence:Now suppose someone comes to me and says, “Give me five dollars, or I’ll use my magic powers … to [harm an imaginably huge number of] people.
Non-Bayesian approaches to evaluating these proposals often take the following form: “Even if we assume that this analysis is 99.99% likely to be wrong, the expected value is still high – and are you willing to bet that this analysis is wrong at 99.99% odds?”
However, this is a case where “estimate error” is probably accounting for the lion’s share of variance in estimated expected value, and therefore I believe that a proper Bayesian adjustment would correctly assign little value where there is little basis for the estimate, no matter how high the midpoint of the estimate.
Say that you’ve come to believe – based on life experience – in a “prior distribution” for the value of your actions, with a mean of zero and a standard deviation of 1. (The unit type you use to value your actions is irrelevant to the point I’m making; so in this case the units I’m using are simply standard deviations based on your prior distribution for the value of your actions). Now say that someone estimates that action A (e.g., giving in to the mugger’s demands) has an expected value of X (same units) – but that the estimate itself is so rough that the right expected value could easily be 0 or 2X. More specifically, say that the error in the expected value estimate has a standard deviation of X.
An EEV approach to this situation might say, “Even if there’s a 99.99% chance that the estimate is completely wrong and that the value of Action A is 0, there’s still an 0.01% probability that Action A has a value of X. Thus, overall Action A has an expected value of at least 0.0001X; the greater X is, the greater this value is, and if X is great enough then, then you should take Action A unless you’re willing to bet at enormous odds that the framework is wrong.”
However, the same formula discussed above indicates that Action X actually has an expected value – after the Bayesian adjustment – of X/(X^2+1), or just under 1/X. In this framework, the greater X is, the lower the expected value of Action A. This syncs well with my intuitions: if someone threatened to harm one person unless you gave them $10, this ought to carry more weight (because it is more plausible in the face of the “prior” of life experience) than if they threatened to harm 100 people, which in turn ought to carry more weight than if they threatened to harm 3^^^3 people (I’m using 3^^^3 here as a representation of an unimaginably huge number).
The point at which a threat or proposal starts to be called “Pascal’s Mugging” can be thought of as the point at which the claimed value of Action A is wildly outside the prior set by life experience (which may cause the feeling that common sense is being violated). If someone claims that giving him/her $10 will accomplish 3^^^3 times as much as a 1-standard-deviation life action from the appropriate reference class, then the actual post-adjustment expected value of Action A will be just under (1/3^^^3) (in standard deviation terms) – only trivially higher than the value of an average action, and likely lower than other actions one could take with the same resources. This is true without applying any particular probability that the person’s framework is wrong – it is simply a function of the fact that their estimate has such enormous possible error. An ungrounded estimate making an extravagant claim ought to be more or less discarded in the face of the “prior distribution” of life experience.
Generalizing the Bayesian approach In the above cases, I’ve given quantifications of (a) the appropriate prior for cost-effectiveness; (b) the strength/confidence of a given cost-effectiveness estimate. One needs to quantify both (a) and (b) – not just quantify estimated cost-effectiveness – in order to formally make the needed Bayesian adjustment to the initial estimate.But when it comes to giving, and many other decisions, reasonable quantification of these things usually isn’t possible. To have a prior, you need a reference class, and reference classes are debatable.
It’s my view that my brain instinctively processes huge amounts of information, coming from many different reference classes, and arrives at a prior; if I attempt to formalize my prior, counting only what I can name and justify, I can worsen the accuracy a lot relative to going with my gut. Of course there is a problem here: going with one’s gut can be an excuse for going with what one wants to believe, and a lot of what enters into my gut belief could be irrelevant to proper Bayesian analysis. There is an appeal to formulas, which is that they seem to be susceptible to outsiders’ checking them for fairness and consistency.
But when the formulas are too rough, I think the loss of accuracy outweighs the gains to transparency. Rather than using a formula that is checkable but omits a huge amount of information, I’d prefer to state my intuition – without pretense that it is anything but an intuition – and hope that the ensuing discussion provides the needed check on my intuitions.
I can’t, therefore, usefully say what I think the appropriate prior estimate of charity cost-effectiveness is. I can, however, describe a couple of approaches to Bayesian adjustments that I oppose, and can describe a few heuristics that I use to determine whether I’m making an appropriate Bayesian adjustment.
Approaches to Bayesian adjustment that I oppose
I have seen some argue along the lines of “I have a very weak (or uninformative) prior, which means I can more or less take rough estimates literally.” I think this is a mistake. We do have a lot of information by which to judge what to expect from an action (including a donation), and failure to use all the information we have is a failure to make the appropriate Bayesian adjustment. Even just a sense for the values of the small set of actions you’ve taken in your life, and observed the consequences of, gives you something to work with as far as an “outside view” and a starting probability distribution for the value of your actions; this distribution probably ought to have high variance, but when dealing with a rough estimate that has very high variance of its own, it may still be quite a meaningful prior.
I have seen some using the EEV framework who can tell that their estimates seem too optimistic, so they make various “downward adjustments,” multiplying their EEV by apparently ad hoc figures (1%, 10%, 20%). What isn’t clear is whether the size of the adjustment they’re making has the correct relationship to (a) the weakness of the estimate itself (b) the strength of the prior (c) distance of the estimate from the prior. An example of how this approach can go astray can be seen in the “Pascal’s Mugging” analysis above: assigning one’s framework a 99.99% chance of being totally wrong may seem to be amply conservative, but in fact the proper Bayesian adjustment is much larger and leads to a completely different conclusion.
Heuristics I use to address whether I’m making an appropriate prior-based adjustment
- The more action is asked of me, the more evidence I require. Anytime I’m asked to take a significant action (giving a significant amount of money, time, effort, etc.), this action has to have higher expected value than the action I would otherwise take. My intuitive feel for the distribution of “how much my actions accomplish” serves as a prior – an adjustment to the value that the asker claims for my action.
- I pay attention to how much of the variation I see between estimates is likely to be driven by true variation vs. estimate error. As shown above, when an estimate is rough enough so that error might account for the bulk of the observed variation, a proper Bayesian approach can involve a massive discount to the estimate.
- I put much more weight on conclusions that seem to be supported by multiple different lines of analysis, as unrelated to one another as possible. If one starts with a high-error estimate of expected value, and then starts finding more estimates with the same midpoint, the variance of the aggregate estimate error declines; the less correlated the estimates are, the greater the decline in the variance of the error, and thus the lower the Bayesian adjustment to the final estimate. This is a formal way of observing that “diversified” reasons for believing something lead to more “robust” beliefs, i.e., beliefs that are less likely to fall apart with new information and can be used with less skepticism.
- I am hesitant to embrace arguments that seem to have anti-common-sense implications (unless the evidence behind these arguments is strong) and I think my prior may often be the reason for this. As seen above, a too-weak prior can lead to many seemingly absurd beliefs and consequences, such as falling prey to “Pascal’s Mugging” and removing the incentive for investigation of strong claims. Strengthening the prior fixes these problems (while over-strengthening the prior results in simply ignoring new evidence). In general, I believe that when a particular kind of reasoning seems to me to have anti-common-sense implications, this may indicate that its implications are well outside my prior.
- My prior for charity is generally skeptical, as outlined at this post. Giving well seems conceptually quite difficult to me, and it’s been my experience over time that the more we dig on a cost-effectiveness estimate, the more unwarranted optimism we uncover. Also, having an optimistic prior would mean giving to opaque charities, and that seems to violate common sense. Thus, we look for charities with quite strong evidence of effectiveness, and tend to prefer very strong charities with reasonably high estimated cost-effectiveness to weaker charities with very high estimated cost-effectiveness
Conclusion - I feel that any giving approach that relies only on estimated expected-value – and does not incorporate preferences for better-grounded estimates over shakier estimates – is flawed.
- Thus, when aiming to maximize expected positive impact, it is not advisable to make giving decisions based fully on explicit formulas. Proper Bayesian adjustments are important and are usually overly difficult to formalize.
Comments
Note to readers: Holden cross-posted this to another website, Less Wrong, where it has begun to spark some meaty discussion.
Hi Holden,
I think this is a great post. I agree with much of it (especially the spirit of it), but I don’t agree with all of it.
Firstly, what we agree on.
I completely agree that one should adjust one’s estimates in light of one’s prior. For example, if you give someone two IQ tests and they score 150 on one of them, and you are asked to come up with an expected value for their score on the other, you should assume it will be lower than 150. Since we know the underlying distribution here (mean 100, standard deviation of 15) we know that the expected score on the other test will be between the population mean and the score we were told about. This is the same kind of thing as the beer rating example and is a classic case of regression to the mean.
We have been informally doing this at GWWC since well before it launched in 2009. We informally weight estimates towards the mean of our prior distribution for that kind of intervention and we weight them further towards this mean if the evidence for the estimate is weaker. We’ve had a project for formalising this weighting on the back-burner for more than a year now. Our plan was very similar to your work with Dario and when we do the maths on it, we’ll be able to check it against yours. Hopefully the formulae will come out the same.
We presumably use a different prior to you, but are definitely using this same strategy of weighting things based on priors. Indeed Will Crouch, Nick Beckstead and I are philosophers for our day jobs and have studied Bayesianism and Decision Theory (though we are not specialists in the areas). I have even published a paper on the topic of adjusting naive estimates by taking into account the chance of one’s argument being wrong:
This is all just to say that we are completely on the same page here in this aspect of our methodology. If there are any disagreements on the topic, they are more fine-grained ones about how to form priors or whether one group or the other is neglecting some important issue (which is easy to happen).
In contrast, my points of disagreement will seem rather small and technical. Since it was a long post (and a long comment), I’ll keep it to one:
There is perhaps a conflation of two things in your post: (1) the strategy of determining an expected value for each option and choosing the option with the highest expected value, and (2) the question of how you calculate the expected values. It is not very controversial that one should maximise expected value in this kind of decision making, but of course this is only true if you calculate it correctly. What you (rightly) want to criticise is using raw, unadjusted data for making decisions, instead of correctly calculated expected values.
Toby
On Less Wrong Bongo wrote
I think that he’s right that a careful reading of the post shows that the post doesn’t argue against expected value maximization. In line with Bongo’s second sentence, maybe the post could have been improved by a disclaimer to this effect at the beginning of the article.
Holden,
I think this is a great post. I especially like the idea of applying Bayesian adjustments to the question of helping those close to you (family) as opposed to those far from you (African orphans).
I’m a huge fan of GiveWell. Please keep up the good work.
Ted Gudmundsen
Ithaca, NY
Hi Toby,
It does not seem to me that you agree with the substance of this post. Perhaps you agree that “one should adjust one’s estimates in light of one’s prior,” but:
The above does not show that you reject the idea of a Bayesian adjustment, but to me it does indicate that you are not in agreement on my outline for how a Bayesian adjustment can conceptually can be done and the general principles this implies – in particular, that cost-effectiveness estimates are less useful when they are less precise, and that therefore understanding the precision is crucial when placing heavy weight on them.
If the issue is that you do not accept the formula proposed in the “Applying Bayesian adjustments to cost-effectiveness estimates for donations, actions, etc.” until you have worked out the math for yourself, this is entirely valid, although it may be more efficient to check the analysis we’ve published (which spells out every step) than to do your own analysis from scratch. However, if it is the case that you do not accept this formula, I think your comment overstates our areas of agreement and leaves out the most important area of disagreement.
I agree with Jonah’s response to your last paragraph.
Hi Holden,
While we at GWWC agree that such estimates need to be adjusted, that doesn’t mean that we make the adjustment in every statement we make. Will’s statement was making the point that if a charity spends 70% of its money on something known to be highly effective and 30% on something with unknown effectiveness, the overall effectiveness is bounded below by .7 times the high effectiveness which is going to be very high, and thus that we can recommend it without knowing the unknown effectiveness. There are many other factors that he didn’t mention in that snippet and the adjustments under discussion are just one example. This doesn’t mean that we don’t take them into account.
When we quote cost effectiveness numbers, we quote the raw numbers, because we don’t have any other computed number to use! We often tell people that these are only rough. In the future, we will hopefully develop a calculator for adjusting such numbers for internal use and might also try using these numbers for external purposes as well, but it is difficult as there is a large subjective component to these numbers (from one’s prior) and thus people typically do not like them. In contrast the raw numbers are raw data for other people to use.
Yes, that’s right, and we are very interested in knowing more about the accuracy of these estimates. We’ve certainly done a bit of sanity checking of them, and we’ve looked into a lot of the philosophical aspects of the methodology (DALYs, age weighting, discount rates etc). We’d love to know more about the empirical aspects too!
It is consistent with Bayesian probability, but is not using a prior that is normal or log normal (for very good reasons). In many cases things are distributed approximately normally or log-normally. So analysis like that in your post should work on it. In other cases the distributions are quite different. I hold that you should make the Bayesian adjustment given the type of distribution you are looking at (and I imagine you agree). In the Pascal’s mugger case or the case in my paper, the correct distribution is not log normal. I could talk about why, but it would be a bit too off-topic.
I should add that the cost-effectiveness of developing world health interventions is demonstrably not log normal either, though I think it is a very useful approximation. It goes wrong at the lower end because some interventions have negative net effects. It goes wrong at the top end because some interventions have infinite, or arbitrarily high cost effectiveness. This is because they may end up being cost-saving or have cost-saving aspects which almost completely balance their costs.
I don’t know how you could think that I would disagree with this. As I explained above, I’d go further than saying they are less useful, and say that in some cases I’d use a value lower than the raw one (I’d use a higher one when the raw estimate is below average). I’d even use a very similar approach to the one here for the DCP2 figures, assuming a roughly log normal prior.
I like this Bayesian model, and I think it is worth applying it to the charities that Giving What We Can recommends, but GiveWell does not. I’m not affiliated with either, and so I’m not speaking for either of them; this is just what I believe to be a faithful representation of the underlying thinking of the two groups, though there would probably be quibbles over some of the numbers I’ve chosen. I’ll ignore finicky details like what happens in the tails of the distribution, etc. My goal is to work out the prior expectation values are.
[Note: I use base-10 logarithms throughout this comment. If I say that x is 0.5 orders of magnitude greater than y, then I mean that log(x) = log(y) + 0.5.]
I’ll use (to make the numbers easy) an approximate value of $100/life saved as the DCP2 estimate for schistomiasis charities.
Assumptions of what I understand GiveWell’s framework to be:
1) DCP2 estimate comes from the high end of cost-effectiveness, say the top 5%.
2) Each charity working on schistomiasis has its own cost-effectiveness, and the middle 95% of charities would cover 4 orders of magnitude.
3) This distribution of cost-effectiveness is log-normal
Assumptions 1) and 3) imply that the DCP2 estimate is equivalent to a charity about 1.65 standard deviations better than the mean.
Assumptions 2) and 3) imply that 1 standard deviation is 1 order of magnitude (95% of a normal distribution is within 2 orders of magnitude of the mean; 2 standard deviations either side of the mean makes 4 standard deviations).
So, this allows us to calculate the expectation of the prior. The mean of the log distribution is
log(DCP2 estimate) + 1.65*1 = log(100) + 1.65 = 3.65.
So, the prior expectation in dollar terms is 10^3.65 = $4500/life saved.
This is well above the demonstrated cost-effectiveness of the top GiveWell charities, so GiveWell won’t recommend a charity based on a DCP2 estimate of $100/life saved.
———-
Giving What We Can disagrees with both of assumptions 1) and 2). I am more interested in assumption 2), and I think this is the big underlying point of disagreement. That is, I want to know what happens to the prior expectation if we believe that the spread of cost-effectiveness is significantly less than what GiveWell does. From what I gather, GWWC would say that the middle 95% of charities cover only 1 order of magnitude in cost-effectiveness. This would make the standard deviation 0.25 orders of magnitude, and so (keeping assumption 1) in place) the mean of the log distribution becomes
log(DCP2 estimate) + 1.65*0.25 = 2.41,
and so the prior expectation is 10^2.41 = $260/life saved.
———-
If instead we believe that the middle 95% of charities cover 2 orders of magnitude, then it works out to 2 + 1.65*0.5 = 2.825, and a prior expectation of 10^2.825 = $670/life saved. If they cover 3 orders of magnitude, then it’s $1700/life saved.
———-
So the prior is very important….
(Of course, GiveWell also care about setting the right incentives for charities, etc. I just wanted to look at the specific disagreement over priors.)
It’s really fascinating to see the volume and range of responses to this post here and on Less Wrong. I wanted to share my own thoughts, which have a definite subjective perspective and should be seen as separate from the (purely analytical and objective) math that I provided for the post.
Both here and on Less Wrong, many people have pointed out that they think this post conflates (1) philosophical objections to the expected value framework with (2) practical objections to the way some particular expected value is calculated. Toby and Bongo here, and David Balan at Less Wrong, express these views clearly and concisely:
These objections might seem to relate only to the presentation of the post, but I think they actually get at a very fundamental difference in intellectual traditions, which I believe is key to this debate.
In my view, Holden is not saying either (1) or (2), what he’s saying is more like (3) “maximizing expected value may be the correct goal in an abstract philosophical sense, but in practice explicit expected value calculations are as a rule misleading, because they’re just too hard to compute. Other tools such as heuristics and intuition tend to be more reliable. Expected value as a goal is fine, but expected value as an operating framework (where one writes down probabilities and payoffs explicitly) is very often not”. This is a practical objection(commenters are correct to say it doesn’t challenge any fundamental philosophical claims), but it’s also a very general objection, and I don’t think it should be dismissed as a simple technical point.
Often there are many different valid ways to view a problem, and many levels of abstraction on which it is possible to operate. Given certain axioms every decision problem can be cast in terms of expected value maximization (just as every physical system can in principle be analyzed in terms of elementary particles) but it’s not always useful or computationally feasible to do so. Often it’s better to think in terms of higher-level concepts, like economic equilibrium, incentives or psychology. These concepts can approximate the result of an expected value calculation without ever actually multiplying out any utilities. For example, what is the expected value of promoting the rule of law in a country? Of improving incentives in the nonprofit ecosystem? Of building a community of people who care about efficient philanthropy? All of these achievements lead eventually to concrete positive outcomes, but it’s hard to calculate those outcomes explicitly, as they involve subtle changes in the actions, social norms, and thoughts of millions of people. As an approximation it may be easier to think in terms of rough common sense concepts — positive incentives are good, society-wide social stability is really good — rather than the abstruse mathematics of expected utility calculations.
The point I wish to make is that these “mere” practical questions are every bit as important as the fundamental philosophical questions. How I decide to approximate expected value (e.g. do I compute it explicitly, or using some very rough heuristic that never involves any numbers?) can have equal or greater effect on the final result as whether or not I am risk averse. Furthermore (though this is beyond the scope of my comment), it’s my view that the practical issues can often be inextricably tied with fundamental philosophical issues — it isn’t always possible to separate the two when practical issues (such as human nature and game-theoretical or social considerations) occur with such regularity that they might as well be fundamental.
So I believe it’s mistaken to dismiss what Holden is saying as merely an objection to a specific kind of expected value calculation. Instead, I believe he’s making the fundamental point that thinking in terms of expected values may be thinking on the wrong level of abstraction. Like trying to explain World War II by simulating all the elementary particles on earth, it’s valid in principle, but computationally infeasible, and any attempt to do it will lead in practice to bad results. It will also lead to uninsightful results — models on the wrong level of abstraction make it very difficult to actually understand the process they are modeling. I feel this way about even the most sophisticated estimates for health intervention DALY’s — the number alone (even if I trust it) feels much less helpful to me than knowing the qualitative details of how the health intervention is implemented on the ground.
I think there’s plenty of room to agree or disagree with Holden’s point depending on the specific case (I certainly feel there are cases where explicit expected value is appropriate and cases where it is not, though I won’t disguise that I am mostly in agreement with Holden in the case of charity evaluations), but it seems to me that this is the central contention that we should be focusing on resolving.
Nick’s quote here:
and Holden’s quote here:
are saying pretty much opposite things, and each seems applicable in certain cases but not in others, so the question is which applies more to charity.
This comment is already too long, but to close I just wanted to say that I’m really happy that this debate is happening — efficient philanthropy is still in its infancy, and it’s good to see meaningful engagement between two slightly different philosophical approaches within a context of broad agreement about the need for efficient and well-targeted giving.
I responderd here
Dario,
Thanks for drawing attention to this issue. I personally think that a hybrid approach is best.
The problem with using unquantified heuristics and intuitions is that the “true” expected values of philanthropic efforts plausibly differ by many orders of magnitude and unquantified heuristics and intuitions are frequently insensitive to this. The last order of magnitude is the only one that matters; all others are negligible by comparison. So if at all possible, one should do one’s best to pin down the philanthropic efforts with the “true” expected value per dollar of the highest (positive) order of magnitude.
It seems to me as though any feasible strategy for attacking this problem involves explicit computation.
There’s no overt contradiction between what I’ve written so far and any other statement on this thread. GiveWell does implicitly uses explicit calculations by imposing the standard that a charity working in international health should save a life for under $1000. Quantitative factors appear to have played a major role in GiveWell’s (list of priority programs for international aid).
GiveWell’s reliance on a rough “$1000/life saved” cutoff seems to me to be close enough to be the best that one could hope for from an international health charity so that I doubt that GiveWell’s use of this heuristic has systematically cut the “true” cost-effectiveness of GiveWell’s charities relative to what they would be with the application of a more quantitative rubric.
However, my feeling is that more detailed use of quantitative modeling will be useful for choosing between global catastrophic risk reduction efforts and for comparing their cost-effectiveness with that international aid. This may be a controversial point.
There are many ways to improve on naive Fermi calculations:
—
1. One can improve one’s general ability to estimate probabilities by practicing generating predictions with confidence intervals and checking them for accuracy.
2. One can carry out explicit Bayesian
discounting as in the present post.
3. One can make a detailed investigation of what subject matter experts think and why they think what they do (this will of course frequently miss out on implicit knowledge).
4. One can explicitly quantify some of the relevant psychological, social and economic factors.
5. One can build an model (either explicit or implicit) weighing the results of an explicit calculation among other factors such as popular opinion and the decisions of others who share one’s values and giving strong intuitive aversion veto power.
In this direction I like Holden’s remark
—
I find it implausible that one can do a better job reducing existential risk using unquantified heuristics and intuition alone than one can by augmenting these with the refined use of explicit cost-effectiveness calculations.
Jonah:
To be clear, nothing I’ve said in my comment argues against the practice of computing expected value estimates and taking them into account in some capacity. It’s just that, as Holden puts it in the title, the numbers shouldn’t be taken literally in many contexts. They can certainly inform decision making, especially when they raise red flags, but they are rarely decisive.
That said, I think part of my objection is more to the language of expected value maximization than to the actual content. When I think of people who’ve had a large positive impact on the world, or even just accomplished a lot for themselves, I rarely see them explicitly talking in terms of expected value (though with some exceptions where the decisions are inherently very quantitative in nature, for example high-frequency trading). Rather, people seem to have a good horse sense for large effect sizes vs small effect sizes based on looking at the evidence. In practice their decisions do a good job of maximizing (in order of magnitude) expected value, but they don’t usually multiply out probabilities or utilities. They certainly do use numbers, but not in such a direct or literal fashion. Fermi calculations, properly used, are actually a good example of this.
I think that one possible reason why the language of expected values and utilities isn’t more used is that there’s a dangerously seductive quality to this language. Even if one fully understands the complexities involved, something about the mode of discourse tends to promote oversimplification. Once you start writing down numbers and probabilities, there’s a temptation to take them literally and start plugging them blindly into formulas, even when you know you shouldn’t. All the caveats and uncertainties seem to disappear, because the numbers are right in front of you and they give such temptingly decisive answers. I do think that many smart and effective people are running something like a sophisticated expected value calculator in their heads, but it’s one that’s well integrated with their intuition, and explicit verbal or written calculations are probably very crude by comparison.
Since you bring it up, I actually disagree that choosing between global catastrophic risks and international aid is best done via detailed quantitative modeling. It certainly makes sense to do some back of the envelope calculations, but in the real world there are a number of practical obstacles to making progress on risks to humanity which I consider much more important than detailed quantitative modeling. Most of the extreme technologies or threats that people have proposed are both poorly understood and relatively far off (in some cases, it’s unclear if the threats are even real). If we understood the future dangers of, say, advanced biological warfare well enough to meaningfully counter those threats right now, then doing so seems like a really good bet, regardless of any detailed calculations. On the other hand, until we have enough understanding to act, a detailed model of the situation isn’t particularly illuminating (and is likely to be wrong). It’s evident to me that biological warfare is an enormous potential problem that (thankfully!) seems to be too far in the future for us to do much about it now (though I suspect we can and should take certain basic precautions, many of which have to do with government protocol or rules regarding government-funded research). The problem isn’t the cost effectiveness, it’s whether it’s possible to address the problem at all. If it is, I’m confident that a detailed cost-effectiveness calculation would show that it’s the right thing to do. If not, then for now there’s nothing to talk about.
Furthermore, I wonder about how much, in practice, international aid dollars are in any sense competing with “existential risk reduction” dollars. The things that we can do right now to address the biowarfare problem seem like mostly things that only the government (or maybe the scientific community) can or should do. It’s unclear what private individuals can do to help. And, conversely, when and if the danger becomes clear and present, the military is likely to spend hundreds of billions of dollars on the problem, and it’s again unclear what a private individual will be able to do to help. There may be some window where private donations can have an impact, but even then I suspect it’s going to be difficult. Perhaps the only people well-equipped to help will be those who have direct experience in biotechnology.
All this is just to say that I don’t think I’m ever likely to face a meaningful practical choice between an existential risk reduction charity and a poverty alleviation charity. There are some existential risks that I take seriously now — mainly asteroid impacts and nuclear war — but the former is very low probability (and already has some resources directed towards it) and the latter is probably best addressed through the political system. More broadly, I think that at the present time in history, the most effective thing one can do to alleviate future threats to humanity is simply to do one’s part to promote a politically, economically, and socially healthy world. This accords with both common sense and back-of-the-envelope calculations.
Also, of the five points you mention, I have to say that I’m skeptical of most of them as a useful or reliable tool for improving explicit expected value estimates. The problem with (2) is that, as Holden says, it’s very difficult to quantify all the information necessary to properly do the Bayesian adjustment — the process is just too error prone. My understanding of the post (and certainly my intention in writing the math) is that the Bayesian adjustment is done only to make the demonstrate that the EEV estimate is misleading. It’s much harder to use this adjustment in an actual precise computation.
Consulting subject experts (3) is certainly a good idea.
(1) is an abstract mental exercise that I would need a lot of evidence to be convinced had any actual value in the real world. If you can do it reliably, you should be able to make a lot of money in the stock market.
As for (4), and (5), it’s just really hard to build such models or make such explicit estimates in a meaningful way. I’d argue that (5) is a good decision algorithm in the sense that it’s what I think a lot of smart people’s brains do, but I’m skeptical that writing it all down with some formal weighting function or veto algorithm is likely to improve the process.
Dario:
I’m not sure that we have a substantive disagreement; but just to tie up loose ends:
1. I agree about the perils of the use of language/formalism of expected utility (there are issues of anchoring biases, etc.).
2. Regarding whether it’s currently possible to do anything about x-risk: I’m particularly interested in nuclear war (essentially for the reasons that you give) and plan on doing a detailed investigation of it and related nonprofits over the next year.
3. Regarding the apparent nonexistence of tradeoffs between international aid and x-risk: I could imagine the existence of some sort of advocacy nonprofit which has a track record of success and room for more funding. Conditional on the existence of such an organization, there would be the question of whether it’s a better investment than VillageReach; this is a hypothetical situation in which I would guess that quantitative modeling would be relevant.
4. Concerning my list of ways that one could improve explicit expected value computations while it may have looked like a laundry list of tasks to complete; my reason for making it was to make a case for the relevance of quantitative reasoning despite the frequent absurdity of naive Fermi calculations.
Regarding (1) my initial intuition was the same as your own but I’ve become less sure. Jane Street Capital allegedly uses this activity to train its employees. I’ve recently seen some informal evidence that there is an underlying broadly applicable skill. But you may be right.
Regarding (2), I believe that there’s at least one instance in which GiveWell is applying your formula in practice. I share your feeling that a field visit would be more useful than a formal Bayesian adjustment of the cost-effectiveness estimate.
Regarding (4), I partially agree and you may be right in entirety but I’m not at all convinced that relevant modeling can never be done. Carl Shulman started a sequence of blog posts arguing that political involvement, contributions and advocacy of the appropriate types can save lives in the developing world at less than $1000/life. I could imagine this being an example of data driven quantitative analysis yielding a solid result. Unfortunately he hasn’t completed the sequence.
Regarding (5); I share your feeling that attempting to write down a decision algorithm is unlikely to improve the process.
After re-reading some of the earlier discussions, I realised that in writing my earlier comment, I missed one of Holden’s key points, namely that you have to Bayesian-adjust the DCP2 estimate. This was more involved than I thought it would be, but I’ve had a crack at it here.
In his (recent Less Wrong post Yvain quoted some research results which can be read as supporting Dario’s position:
But maybe the discussion on this thread is too vague and abstract to be useful. Everybody agrees that quantitative analysis should be used and that philanthropic decisions shouldn’t be made exclusively based on narrow quantitative models. Any disagreement is about more subtle matters that are harder to pin down. Moreover, owing to the gap between mental models and verbal expressions of them, apparent agreement or disagreement may not be what it appears to be.
In practice what one wants to do is to choose between particular charities. This can be discussed on a case by case basis. I don’t currently have a broadly compelling case for any particular charity being a better investment than VillageReach or Against Malaria Foundation are.
Choosing a prior is difficult. However, perhaps there’s an artificial way to do it that might work well enough for GiveWell’s purposes?
Suppose we say that we’re having a contest to pick the “charity of the year”, out of N entrants. Then we can start out saying that each charity has a 1/N chance of winning the contest. Then it’s a matter of estimating how many charities there are that you could possibly consider, and giving each of them a fair chance.
The reason this works is because we arbitrary decide there will be one winner, but that seems reasonable – we want to make a recommendation, after all. There is a bias against doing nothing.
It’s still very difficult to estimate how many charities there are that we consider to have entered the contest, but it is at least something that it’s possible to have a reasonable debate over.
Thanks for the thoughtful comments, all. FYI, there are also interesting discussions of this post up at Less Wrong (as Luke notes), Overcoming Bias and Quomodocumque (including Terence Tao’s thoughts on “Pascal’s Mugging”).
Toby:
First, I’m still not clear on whether you agree with the specifics of the post above – by which I mean the specifics of how a Bayesian adjustment ought to be done, not just the notion that Bayesian priors need to be taken into consideration. I’d appreciate clarification on this point.
Second, I think it is worth noting that Will’s 2010 comments appear inconsistent with the reasoning of this post (not just neglecting to mention it). He argues that even a deworming charity known to be wasting 26% of its money “still would do very well (taking DCP2: $3.4/DALY * (1/0.74) = $4.6/DALY – slightly better than their most optimistic estimate for DOTS [$5/DALY]” and concludes that “the advocacy questions [relevant to whether this 26% is spent effectively] don’t need to be answered in order to make a recommendation.” This is a much stronger statement than the one you attribute to him and seems to require taking the estimates literally. Furthermore, in another exchange around the same time, he states that “uncertainty counts against an intervention only if the uncertainty is either symmetrical (and one is risk-averse), or if the uncertainty is asymmetrical, biased towards lower-cost-effectiveness” – a statement that seems inconsistent with a Bayesian adjustment. In a later comment he stated that “the highest estimates will likely be over-estimates; the lowest estimates will likely be underestimates” but he never retracted his claim that symmetric uncertainty is irrelevant to a risk-neutral donor.
So GWWC has made statements that seem inconsistent with the argument of this post. More important in my view, though, is that GWWC hasn’t published any discussion of these issues as they relate to its charity recommendations. In particular, it hasn’t published any content on how much “estimate error” it feels is reasonable to assume in the DCP2 estimates, and why – a particularly important input given how much weight GWWC appears to put on these estimates and given the issues we’ve raised with these estimates in the past.
If you do agree with the framework laid out in this post, I suggest adding content to your website acknowledging as much and discussing your view/reasoning re: how precise and reliable the DCP2 estimates are.
One more minor point: I do believe that a log-/normal distribution is a more reasonable approximation when dealing with existential-risk-type cases (or “Pascal’s Mugging”) than you seem to (more at my comment response on Less Wrong), and I also believe that most of the arguments of this post do not hinge on having a log-/normal distribution. This includes the argument that the framework your paper uses for accounting for model uncertainty is problematic because of the way it can frame over-aggressive claims in a way that looks “conservative.”
Dario and Jonah: very interesting exchange on the appropriate role of formal calculations. I think the three of us are in agreement that the language of expected value is conceptually OK but practically problematic, but that expected-value calculations can play an important role when used appropriately (and not literally). I’ll just add that this post was largely intended as a rebuttal to a particular objection to Dario’s first comment. The objection is something along the lines of, “while many aspects of a decision can’t be quantified, we can use the quantifiable part as our ‘expected value’ as long as the unquantifiable parts seem as likely to point in one direction as in the other direction.” I believe the above post shows why this idea is flawed.
David Barry: I’m with Dario when he says that the best use of the formula presented here is to make an argument against formal calculations and for the heuristics I list. My concern is that focusing on these numbers obscures important questions like “How well does the DALY metric itself approximate ‘good accomplished?'” and “How significant are the factors being left out of DCP2 estimates?”
That said, I did play with a formalization of the Bayesian adjustment in the case of the DCP2 estimate, and discussed it some with Toby offline; I can forward you our exchange if you’re interested and if Toby agrees.
Brian, I don’t think this is a good idea. Picking a prior “artificially” works against the goal of incorporating all the information at our disposal – including non-formalizable information – into the best view possible. My life-experience-based prior over the impact of my actions is difficult to formalize but is information that should be used, not purposefully discarded in order to have a simple prior.
Hi Holden. Thanks: I’d be interested to see the discussion with Toby, if Toby’s happy with that.
I generally think that intuitions and subjective beliefs can be (approximately) modelled. Though it’s always good to be sceptical of any formalisation, sometimes the process shows up a fundamental disagreement, and roughly how important that disagreement is. And some people’s intuitions are wrong! So I think it’s a worthwhile exercise for someone to try… even if I only have myself for an audience.
Hi David,
I agree with you about the benefits that formalization can have, but I think there are times where it obscures more than it clarifies and that this is one of those times.
For example, some of the main reasons I find bednet distribution to be more promising (from a cost-effectiveness perspective) than deworming are:
All of these points relate to the variance around estimated cost-effectiveness, which means they relate to cost-effectiveness properly understood (e.g., conceptually computed along the lines of this post). Any formal calculation that leaves these factors out will be flawed, but I have trouble imagining a formal calculation that puts them in in a reasonable way. It’s hard for me to quantify what I think the implications are for variance; I haven’t seen a standardized unit for “good accomplished” (including DALYs) that I find intuitive enough to discuss the quantified variance of usefully (except by examining the calculation itself and looking for sources of variance in that – but the above factors can’t be dealt with in this way).
If you do think it can be done reasonably, I’m open to hearing the proposed method.
Note that the above still pertains to a relatively abstract and idealized question (“bednets vs. deworming”). The situation seems to become even more difficult to model when we start incorporating our observations of actual organizations.
That’s fascinating, and I appreciate you taking the time to reply in such detail. When it comes to helminth infections and so on, I’m a long way out of my depth. Without a lot of study, I don’t think I can even form an opinion on the various factors you mention, let alone wonder if it’s possible to usefully model them.
I’m glad that there are groups (well, GWWC at least…) who have a differing philosophy with similar broad aims, but I’m more persuaded than I was that GiveWell’s approach yields better results, in terms of expectation values as well as incentives.
Holden:
Regarding deworming vs. bednet distribution, I don’t necessarily disagree with your conclusion, however:
I’m somewhat puzzled here, there have been studies of national deworming programs in each of Kenya, Burkina Faso, Uganda, Myanmar, Cambodia, Ghana/Tanzania, Cambodia and at least one one randomized controlled trial. The results have varied somewhat but I haven’t seen any study that’s seriously called the effectiveness of school based deworming into question. Can you give a reference for the Cochrane Review?
Jonah,
By contrast, studies of national bednet distribution programs demonstrate impressive drops in mortality, as discussed in our writeup on bednet distribution campaigns.
Nobody questions the idea that school-based deworming results in a short-term reduction in the prevalence and intensity of worm infections. But evidence for a link from this to improvements in mortality and morbidity is much thinner.
My guess is that it doesn’t change anything qualitatively, but the math in the linked paper is wrong, or Wikipedia’s article on the log-normal is wrong, or I am wrong.
The paper claims that the distribution of the log of the error is normal with mean 0 and nonzero standard deviation, but that the distribution of the error is log-normal with mean 1. These can’t both be possible; a log-normal distribution’s mean is e^(u+s^2/2) where u is the mean of the log and s is the standard deviation of the log.
Guy, when referring to the “mean” of the lognormal distribution, I assume that Dario meant “median.” This would be consistent with the rest of what he wrote.
I took “the measurement is unbiased” to translate to E[Mi]=Ti, which requires E[Ei]=1 rather than the median equaling 1.
In any case I did some calculations in Excel to see posterior estimates using lognormals with the E[Ei]=1 requirement and (if I did them right) qualitatively the point still stands, within the model it’s very hard to see large posterior estimates when measurement uncertainty is high enough.
Having thought through various catastrophe scenarios over the past few months I’m moderately confident that:
(a) The error bars surrounding the cost-effectiveness of present day efforts to avert catastrophe due to future technologies are huge.
(b) The probability of human extinction due to advanced technologies is (at least) three orders of magnitude greater than that of human extinction due to currently well understood risks.
In light of (a) and (b) I think that there’s a strong case for building a community of people who are interested in effective philanthropy being more cost-effective than present day direct efforts to avert human extinction. A community of people who are interested in effective philanthropy is highly fungible as it can shift its focus as new knowledge emerges and the error bars attached to the cost-effectiveness of a particular intervention shrink.
The skills that people develop in the course of studying and analyzing existing philanthropic efforts seem to me to be likely to partially transfer over to the analysis of the effectiveness of future philanthropic efforts.
I would guess that the expected value of networking/researching/advocacy connected with effective philanthropy is (at the margin) orders of magnitude higher than the direct impact of charitable contributions to effective organizations that work to improve health in the developing world. However, it’s unclear to me that money is the limiting factor here rather than skilled and motivated labor. If the cause of increasing focus on effective philanthropy lacks room monetary funding, one is still left with the question of where to donate.
Ignoring the idiosyncrasies of human psychology I think that the expected value of donating later would be much higher than the expected value of donating now. However, my own experience is that saving to donate later carries cognitive dissonance which reduces my own interest in effective philanthropy. I imagine that this is the case for most other people who are interested in effective philanthropy as well (although I may be wrong). As such, I would guess that it’s generically better for people who are interested in effective philanthropy to donate now rather than later.
Moreover, without making donations in real time, one is unable to track the outcomes of donating with an eye toward accountability (as GiveWell did with VillageReach during 2010) and this diminishes the quality of the information that one can gain by studying existing philanthropic opportunities.
tl;dr: Barring the existence of exceptionally good present day catastrophic risk reduction interventions it seems that the highest utilitarian expected value activities are to gain practice at analyzing existing philanthropic opportunities for which there is good information available and to involve others in the community.
Jonah, thanks for the thoughts. I want to note that GiveWell’s money moved figure is crucial to our influence and access. So for one whose primary interest is in making GiveWell more influential, and not in improving lives in the developing world, this is an additional argument for donating to our top charities.
This is one of those cases where I am not sure whether the research I read is simply old and superseded or whether it is old and useful but not widely known outside the domain of decision theory.
I would like to refer to the possibility of using improper linear models in evaluating charities. As research indicates, especially when dealing with a decision involving multiple psychologically incomparable criteria as is the case e.g. when comparing charities, predictions of improper linear models consistently outperform the results of experts’ global judgment in many domains. The reason is precisely that explicit formulas reliably eliminate circumstantially introduced inconsistencies which an intuitive global judgment will create, even when based on Bayesian procedures.
The concept is described and evaluated in the linked paper “The Robust Beauty of Improper Linear Models in Decision Making” (1979) by Robyn M. Dawes (citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.188.5825&rep=rep1&type=pdf). It is also described in more detail in Rational Choice in an Uncertain World: The Psychology of Judgment and Decision Making, a book by Dawes and Reid Hastie which also deals with Bayesian adjustments to some extent. Chapter 3 of this book’s second edition comes to the bold conclusion that “Whenever possible, human judges should be replaced by simple linear models.” Many criticisms are also rebutted in chapter 3.6 of the book, of which there is an amazon preview online.
The method is also mentioned in Kahneman’s “Thinking, Fast and Slow” (2011), and a one-page manual is found under “Do it yourself” in the subchapter “Intuitions vs. Formulas”, also available as an amazon preview.
The reason why I do not explain it here in detail is simply because I am not sure about the problem stated in the first paragraph of my comment. Should it indeed prove to be a new point in the overall discussion, I will be happy to provide more detail.
Hi Tobi,
I’m familiar with some (though not by any means all) of the discussion around simple linear models, and agree that in some cases they can outperform expert judgment. I’m not sure I see the relevance to the main argument of this post, however. “Simple linear model” is a very different idea from “explicit expected value”; in many cases an “explicit expected value” calculation is quite complicated and/or takes intuitive judgments and guesses as many of its inputs.
Comments are closed.